
Modèle de langue, séquence de mots,… Les N-grams accompagné de Perceval le Gallois !
C’est en compagnie de Perceval de Galles que je vais aborder le sujet des Ngrams. Modèle de langue, séquence de mots, probabilité d’occurrence… On est pas mal avec tout ça ! C’est parti pour un article encore une fois très branché… Maths.
Petite introduction aux modèles de langues

Mais non ne t’en fait pas Perceval… Les ngrams… C’est un terme un peu barbare dit comme ça, mais pourtant pour Google, c’est quelque chose d’assez naturel. Google a mis à disposition en 2010 un outil permettant de suivre l’évolution de la fréquence de un ou plusieurs mots dans une langue. Grâce à son service « Google Books », Google a réussi à mesurer cette évolution linguistique grâce à sa transposition de supports papier en supports numériques. Si Google nomme ce service Ngram Viewer ce n’est pas pour rien… C’est parti pour encore plus de mathématique et de SEO !
Introduction introductive
Avant de parler de Ngrams, on va d’abord s’attarder sur deux notions :
Modèle de langue et Séquence de mots.
Un Modèle de langue, c’est l’agencement et la distribution des mots dans une langue. En français on appellerait ça pour faire simple la syntaxe et… la distribution des mots 🙂 Les modèles de langues impliquent la probabilité d’observer une séquence de mots dans une langue (/!\ Important à retenir ça).
On en vient à la séquence de mots, qui elle définit un enchaînement d’un, deux, trois… mots.
Ce qui va nous intéresser pour la suite de l’article, ce sont avant tout ces deux notions là. En effet, elles sont une des clés de l’évolution du langage. Bien que cela entraîne la notion de probabilité, cela reste tout de même très concrets, ce qui peut paraître paradoxale lorsque l’on parle de probabilité… mais bon c’est ça qui est cool ! Dans un modèle de langue, ce qu’on cherche à définir c’est la probabilité qu’une séquence de mot peut être produite. Est ce que l’enchaînement de ces mots est probable ? Mathématiquement on écrit ça de cette façon : P(s|M)
P pour la probabilité
s pour une séquence de mot
M pour un modèle (soit une langue)
On lit ça de cette manière : « La probabilité d’observer une séquence s, dans un ensemble M (ici, la langue analysée) »

Ba quoi Perceval, c’est « probabilité » que tu comprend pas ?
Et maintenant, place aux Ngrams
Une séquence de mot peut se composer de différents éléments. En effet, une séquence ne peut représenter qu’un seul mot (un modèle unigram), une séquence peut représenter deux mots (un modèle bigram), ou une séquence peut représenter « n » mots (un modèle n-gram). Pour rappel, en mathématiques, lorsque l’on veut attribuer dans une formule un nombre quelconque, on utilise la lettre « n » (un peu lorsque l’on dit un « n-ième » machin…). Dans le cas des n-gram, « n » est forcement supérieur à 2 (ba oui puisqu’on a unigram et bigram avant 😉 ). Et bien voilà ils sont là ces bons vieux Ngrams !
Petite aparté : Pour le reste de la démonstration, je ne vais me référer qu’à l’exemple des unigrams. Oui parce que vulgariser les formules mathématiques des ngrams, c’est pas une mince affaire… Et la logique du raisonnement reste la même lorsque l’on se réfère aux unigrams.
Les tailles de séquences
Dans le cas d’un unigram (séquence d’un seul mot), chaque mot est indépendant, et ne dépend d’aucun autre (/!\ Important à retenir ça aussi). On dit alors qu’il n’y a pas d’historique, et donc pas de successeur. La somme des probabilités d’apparitions d’une séquences dans un modèle unigrams est égale à 1. La totalité des probabilités de trouver un mot dans un corpus est toujours égal à 1. Mathématiquement on écrit ça de cette façon : P(m1) + P(m2) + … + P(mn) = 1.
A lire de cette façon : « La probabilité du mot 1 + la probabilité du mot 2 + … + la probabilité du nième mot = 1 »
Cette équation est assez simple à comprendre dans le cas des unigrams. Il faut savoir que pour des bigrams ou des ngrams, la somme des probabilités est aussi égal à 1.

Exemple
Et oui Perceval, c’est pas tout à fait faux ce que tu viens de dire. Prenons un exemple. On observe qu’un texte de 30 mots (qu’on nomme M) contient les mots suivants (qu’on nomme m). La colonne de droite représente leur probabilité d’apparition P(m|M) (soit la probabilité de voir apparaître m dans M)
| m | fréquence d’apparition | Probabilité d’apparition P(m|M) |
| SEO | 8 | 8/30 |
| Référencement | 4 | 4/30 |
| Blackhat | 4 | 4/30 |
| Whitehat | 3 | 3/30 |
| SEA | 3 | 3/30 |
| Stratégie Web | 2 | 2/30 |
| 2 | 2/30 | |
| Altavista | 1 | 1/30 |
| Backlinks | 1 | 1/30 |
| Microformats | 1 | 1/30 |
| Ranking | 1 | 1/30 |
On en déduit donc que P(m1|M) = 8/30. La probabilité que le mot SEO apparaisse dans ce texte de 30 mots est de 8/30. Si j’additionne toutes les autres probabilités, j’arrive bien à 30/30 soit 1.
Conclusion : les probabilités d’une taille de séquence sont bien toujours égale à 1. Maintenant qu’on sait ça, c’est cool. Mais comment on peut déterminer une probabilité d’apparition d’une séquence ? C’est ça qui nous intéresse pour comprendre la fourberie de Google !
Probabilité d’apparition d’un mot dans un modèle unigram
Pour déterminer une probabilité d’apparition d’un mot, on va en réalité chercher à déterminer une probabilité d’occurrence d’un mot dans une séquence. Une telle probabilité s’écrit mathématiquement :
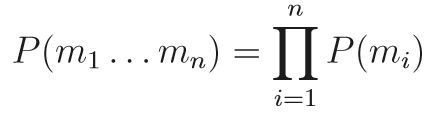
Comme dirait un certains Perceval de Galles (ou Provençal le Gaulois, ça dépend des régions… y’en a d’autres c’est ducon…) :

Plus sérieusement ça parait un peu barbare comme ça, mais en réalité ça ne l’est pas. Ca donne « Le produit de tout les mots de toutes les probabilités d’une séquence n, sachant que l’addition de cette ensemble vaut 1 ». Si je reprend l’exemple du tableau ci dessus, la probabilité d’apparition d’une séquence de mots SEO, SEA et Google serait :
P(SEO SEA Google) = P(SEO)*P(SEA)*P(Google), soit (8/30)*(3/30)*(2*30) = 48/27000 = 0.0017.
Donc en fait, très peu de chances de retrouver cette séquence au final. Mais l’important n’est pas là. Nous avons réussi à montrer qu’une langue, ce que l’on appelle un modèle, peut être interprétée par des probabilités. En effet, il y a des séquences qui ont une probabilité d’apparition plus forte. La démonstration par le modèle unigram permet de comprendre la mécanique du raisonnement.
Un peu plus haut dans l’article, je vous ai dis que dans un modèle unigram, les séquences de mots ne dépendaient pas les unes des autres. Maintenant, nous allons aller encore plus loin avec les bigrams, et les ngrams. Essayons d’imaginer une même réflexion lorsque une séquence implique un historique dans son analyse. Quelle serait la probabilité d’apparition dans un texte du mot SEO, SI ET SEULEMENT SI, il est suivi de mot « ready ». Vous êtes alors confronté à un bigram. Je vous mets la formule à titre indicatif :
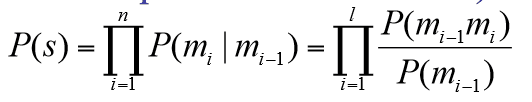
Et si je rajoute encore un paramètre, je suis dans une situation de ngram… Allez, je sais que vous en voulez encore plus, voila la formule :
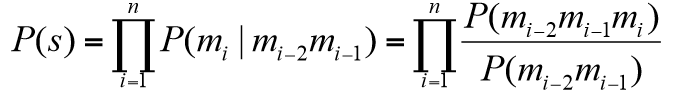

Nous nous retrouvons donc confronté à des modèles de probabilité beaucoup plus complexes (vous comprendrez peut-être mon choix de faire la démonstration avec un modèle unigram ? 🙂 ). complexe certes, mais peut-être plus pertinent. pour être franc avec vous, ce modèle probabiliste possède de nombreuse limite, notamment lié à la pertinence du résultats. Il n’empêche que c’est un modèle qui du point de vue de Google, peut s’avérer pas si limité que ça.
Oui mais alors quoi ??
Des formules, encore des formules… Et le SEO dans tout ça ? Et ba le SEO… Je reconnais qu’on s’en éloigne un peu. Pour être franc c’est pas les ngrams qui vous feront ranker. Néanmoins, ça permet de comprendre une chose. Les ngrams sont souvent associés à la RI : la recherche d’informations. Je vais paraphraser un doc qui pour moi fait le lien avec le SEO :
« [les ngrams] reposent sur l’idée que l’utilisateur, lorsqu’il formule sa requête, a une idée du document idéal qu’il souhaite retrouver et que sa requête est formulée pour retrouver ce document idéal »
Les ngrams impliquent d’autres questions. Comment Google comprend-il votre contenu ? Si une langue, donc un texte dans cette langue définie, possède des probabilités sur des séquences de mots, alors certaines associations de mots sont, si je vulgarise un peu, plus probable que d’autres ? Si Google intègre les ngrams à son algorithme, alors ça veut dire qu’il est capable de reconnaître une suite logique de mot. Et si il enregistre toutes ses probabilités de suite de mots, il peut alors nous suggérer certaines associations de mots ? N’y aurait-il pas un avant goût de Google Suggest ?
Google Suggest repose (à mon humble avis) sur ce principe de ngrams. Et c’est grâce à cette connaissance du langage et de ces codes, que Google est capable de comprendre le sens d’une association de mots et son importance dans la langue, donc le modèle. Attention, ce n’est pas affirmé par Google, j’en fais une simple supposition, qui pour moi tient la route. Il se pourrait tout à fait que cela ne soit pas le cas, mais les ngrams supposent une notion de prédiction.
C’est pourquoi, l’utilisation des synonymes est plutôt une bonne chose ! Car vous donnez à Google une association plus rare de mots. Et on sait tous que Google est très friands de nouveautés 🙂 En fait cette démonstration résulte directement de l’algorithme de Viterbi. Mais on en parlera plus tard de Andrew Viterbi… Ouais on en parlera 😉 . Et sans une introductions aux Ngrams, on aurait eu du mal à en parler… J’ajouterai en plus de Viterbi deux modèles que je n’aborde pas dans l’article, mais qui sont étroitement liés aux ngrams : le modèle de Markov, et le modèle de Shannon. Ils auront certainement un article également pour eux !
Pour infos, vous pouvez consulter les résultats que Google a obtenu des ngrams, suite à son analyse des livres sur « Google books » en suivant ce lien. C’est pas trop mal fait.
Dans tout les cas, si vous êtes arrivé jusqu’ici merci pour votre lecture 😉 C’est pas des sujets qui passionnent tous le monde, mais pour ma part, c’est toujours un plaisir de faire des recherches là-dessus. C’est peut-être même possible que ça se transforme en format vidéo… Ca pourrait être pas mal du tout 😉 A vous de juger ! Je laisse Perceval conclure cet article :

Merci pour cet article très pédagogique. J’ai pourtant souvent interroger beaucoup d' »experts » SEO qui utilisait cette expression sans être capable de me l’expliquer clairement. P(Loup/ »Quand c’est flou c’est qu’il y a un …) >0,9 ? 😉
Comme dit Dobria, j’ai fronce les sourcils et relu n-fois certains passages.Mais Perceval a été le prof qu’il fallait . Merci pour ces explications « humoristiquement illustrées’
bonjour Quentin,
Merci pour ton article, je suis en pleine quête de connaissances SEO en ce moment et je n’arrivais pas à trouver d’articles en Français qui parlent justement des N-grams. A ton avis, comprendre la logique des N-Gram peut-elle influer la façon dont on aborde la rédaction de contenus ?
Hello Benjamin,
Alors oui et non (comme souvent en SEO ^^)
Oui pourquoi ?
-> La logique Ngram permet de mieux appréhender quelques outils d’analyse sémantique, tel que YourTexteGuru ou 1.fr. Comprendre en fait la façon dont Google va lire et interpréter ton contenu etc…
Non pourquoi ?
-> Ton contenu doit rester naturel, donc la notion de Ngram sera normalement naturel également. La forcer revient à créer ce que Antoine Beyer évoque plus bas, du contenu de mauvaise qualité que Google détectera.
Tout est une question de dosage, comme à chaque fois en SEO ^^ !
Compris ! 🙂
Salut Quentin , l’utilité du ngram algorithm ( je ne parle pas du ngram viewer ) n’est pas de calculer la probabilité d’une séquence de mots mais de calculer la probabilité d’un mot sachant une séquence de (n-1) mots. Donc pour moi il s’en sert clairement pour détecter du texte de mauvaise qualité : si par exemple tu écris » la tulipe est » il y a une probabilité quasi nulle d’avoir le mot » saucisson » , ça lui permet de détecter de la soupe créé à partir d’un spin de mauvaise qualité par exemple
Salut Antoine,
Oui, je suis complètement d’accord avec ta précision. C’est vrai que le calcul de Ngram est une opération effectuée sur la probabilité d’apparition de mots, avec l’antériorité n-1.
Il me semble que ce n’est par contre pas le cas dans le cas des uni-grams. Mais plus dans le cas des bi, tri,… grams. Après le terme Ngram s’utilise pour généraliser ça.
Pour la détection du texte de mauvaise qualité, c’est sûr et certains, Ngram intervient.
Merci pour ta précision ! Comme quoi les commentaires, c’est pas que du Bullshit 😉
Je sui arrivé au bout ! Bon j’ai fronçé 2 ou 3 fois les sourcils quand même. Heureusement que Perceval était là pour nous expliquer.
Il a fait son boulot alors 😉 Heureusement qu’il était là finalement !